
Target Selection in Phonological Intervention
- Details
- Created: Saturday, 12 November 2011 14:51
- Updated on Thursday, 14 June 2018 19:21

Cite this article as:
Bowen, C. (2011). Target selection in phonological intervention. Retrieved from http://www.speech-language-therapy.com/ on [insert the date that you retrieved the file here].
8 Traditional Target Selection Criteria
1. Work in developmental sequence
Working on sound targets in the typical sequence of acquisition is a non-evidence based approach that is adopted on the logical assumptions that earlier developing sounds are easier for a child to learn first, or less frustrating for them to work on, or easier for the clinician to teach (Van Riper, 1978; Van Riper and Irwin, 1958), or any combination of these rationales. This approach to target selection is adopted in Traditional Articulation Therapy.

2. Prioritise targets that are 'important'
The notion of ‘social importance’ usually implies a significant target for the child or family in terms of how the child is perceived, and may relate to the avoidance of embarrassment.
3. Choose targets that are stimulable
Prioritising for intervention stimulable phonemes for which a child has most knowledge is based on the interwoven ideas of developmental readiness, ease of learning and early success as a motivator (Hodson, 2007) for the child, and ease of teaching (for the clinician). Traditionally, ‘stimulable’ has meant that a consonant or vowel can be produced in isolation by the child, in direct imitation of an auditory and visual model with or without instructions, cues, imagery, feedback and encouragement. This approach to target selection is adopted in Traditional Articulation Therapy and in the Cycles (Patterns) Approach.
4. Use words that can be minimally contrasted

Minimal word pairs can be maximally opposed, like chick-lick, which differs in place, voice, manner, markedness and major class, ‘nearly maximally opposed’ like bump-jump which cuts across many featural dimensions but shares the voicing feature, or minimally opposed like coat-goat differing in voice only, dip-zip differing in manner only, and right-light differing in place of articulation only.
Targeting error phonemes, or error patterns, using minimally opposed words is done on the understanding that it is the most direct way of demonstrating (his or her own) homophony to a child (Dean, Howell, Waters & Reid, 1995; Grunwell, 1989, 1995) with nothing else to ‘get in the way’.
Slide Show
Minimal Pairs - Oh boy, it's a test! (17 slides)
Can't open the ppsx slide shows? Go to Slide Show Help
5. Choose unfamiliar words as therapy stimuli
Choosing unfamiliar words or low frequency words (in terms of their usage) for treatment stimuliis based on the premise that a child’s error production of seldom-spoken or novel words (like yowie and yen) will not be as habituated as familiar, ‘often said’ words (such as yes and you and yet).
6. Target sounds the child sometimes says correctly
The principle governing the selection of sounds that are sometimes pronounced correctly is that because the child demonstrates some knowledge of an inconsistently erred target it will be easier to learn and teach than a sound for which a child has least (or no) knowledge.
7. Target the patterns most destructive of intelligibility
Sometimes an error has such a pervasive, negative impact on intelligibility that it compels consideration as a high treatment priority (Grunwell, 1989).
8. Target patterns that deviate most from the norm
On the recommendation of Grunwell (1989) non-developmental patterns are often given priority, particularly Initial Consonant Deletion which is only attested in normal development in Finnish, French and possibly Hebrew; and glottal replacement where it is not dialectal. Non-developmental patterns (Flipsen Jr & Parker, 2008, citing Dodd & Iacono, 1989; Edwards & Shriberg, 1983; and Khan & Lewis, 1983) often beg to be eliminated because they can sound ‘odd’ even to the untrained ear, and they can disrupt prosody.
8 Newer Target Selection Criteria
9. Consider prioritising late developing sounds/structures
Some research suggests selecting, as treatment targets,later developing sounds and clusters, as training them will result in greater system-wide change (Gierut, Morrisette, Hughes & Rowland, 1996).
10. Consider giving priority to marked consonants

Some research suggests we should target MARKED properties in order to facilitate acquisition of unmarked aspects of the system. Markedness is a concept from the study of the sound systems of all natural languages.
A marked feature in a language implies the necessary presence of another feature - hence ‘implicational relationship’.
In markedness theory, in English, fricatives, the voiceless stops that occur in /s/ clusters (the adjuncts), affricates and clusters are ‘marked’.
Confusingly, Jakobson (1963) discussed the stops /p/, /t/ and /k/ as unmarked, and this is common in the linguistic literature. According to David Ingram (personal correspondence, 2011) this general claim, however, is based on languages where the voiceless stops are unaspirated and have roughly a zero Voice Onset Time (VOT). English speaking children start out with stops that are 0 VOT, but English speaking parents (including researchers) hear and often transcribe these as voiced because they are within the VOT boundaries for English voiced stops.
The unmarked stop for English children, Ingram says, is neither the English voiced nor voiceless aspirated stop, but those stops that occur after /s/ in clusters (i.e., /st/, /sp/ and /sk/). Based on judgments of accuracy, the voiced stops in English actually are acquired before the voiceless ones, and can be interpreted as the unmarked ones.
Interestingly, the opposite occurs in Spanish where the voiceless stops are 0 VOT and the voiced stops are prevoiced. Spanish children start out doing well with voiceless stops, which are perceived by Spanish speakers as voiceless, and have errors with the voiced ones, sometimes making them fricatives, something rarely if ever seen in English children.
So the markedness of stops has to be viewed in relation to whether a language has one, two or even three series of stops, and in relation to their VOT values.
Fricatives imply Stops
Target fricatives ‘to get’* fricatives and stops.
Voiceless Stops imply Voiced Stops
Target voiceless stops to get voiced and voiceless stops.
Affricates imply Fricatives
Target affricates to get affricates and fricatives.
Clusters imply Singletons
Target clusters to get clusters and singletons.
* 'to get', here, means 'to achieve generalisation to'
11. Work on non-stimulable sounds
Targeting non-stimulable sounds (to make them stimulable) via exploratory sound production and phonetic placement techniques increases the chances of generalization, once stimulability has been achieved (Rvachew, Rafaat & Martin, 1999).
On the other hand, targeting stimulable sounds yields short term but limited gains, in terms of generalization (Powell & Miccio, 1996).
But note that Rvachew & Nowack (2001) determined that clinicians can be reasonably confident that provided the child has relatively greater productive phonological knowledge for them, developmentally earlier targets will be easier for preschoolers to acquire than targets (phonemes) that are both unstimulable and late-developing.
We know that if a child is not stimulable for a sound there is poor probability of short-term progress with it. The sound is unlikely to ‘spontaneously correct’ or magically ‘become stimulable’.
Since the late 1990s the child phonology literature has encouraged clinicians to target non-stimulable sounds, because if a non-stimulable sound is made stimulable to two syllable positions, using our unique clinical skills, it is likely to be added to the child’s inventory, even without direct treatment (Miccio, Elbert & Forrest, 1999). So treatment outcomes are likely to be enhanced when SLPs/SLTs address the production of non-stimulable sounds.
Stimulability Assessment Form - 1-page pdf
Miccio Character Cards 22 pages - Updated 2012 LARGE FILE download from phono-tx Flies area
Miccio Character Cards 7 page pdf - Updated 2012 - download from this page
About stimulability therapy
12. Use maximally opposed words
A maximal opposition cuts across many featural dimensions. For example the word pair bun-sun differs in place (labial is distinct from coronal), manner (stop is distinct from fricative) and voice (/b/ is voiced and /s/ is voiceless). The contrast fat-gnat is in place, manner, voice and major class (/f/ is an obstruent and /n/ is sonorant), and markedness (/f/ is marked, /n/ is not).
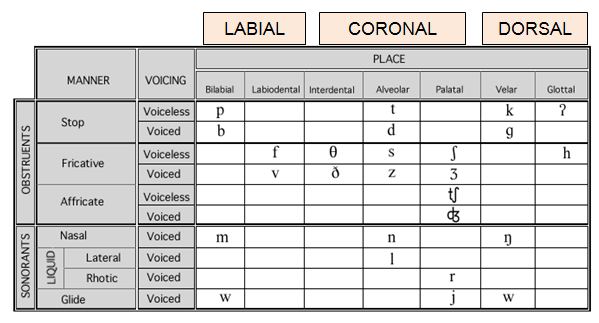
Phonemes are not ‘contrastive’ but their features are. Featural distinctions create an ‘opposition’ between phonemes.
The Non-Major Class Distinctions are in place: differentiating labial, coronal and dorsal consonants; in manner: differentiating stops, fricatives, affricates, nasals, liquids, glides; and in voice: differentiating the voiced-voiceless cognate pairs.
Major Class Features distinguish between the main groupings of sounds in a language: consonants vs. vowels, glides vs. consonants, and obstruents (stops, fricatives, and affricates) vs. sonorants (nasals, liquids, glides, and vowels).
Bake-make illustrates a major class distinction between obstruents and sonorants; make-wake illustrates the major class distinction between consonants and glides. In the minimal pair silly-billy the contrast is not quite maximal, but it is ‘maximal enough’ to be highly salient for a child receiving intervention. In silly-billy we have labial /b/ vs. coronal /s/, stop /b / vs. fricative /s/, voiced /b/ vs. voiceless /s/, and unmarked /b/ vs. marked /s/. It crosses many featural dimensions but /b/ and /s/ are obstruents so there is no obstruent vs. sonorant opposition (i.e., no Major Class Feature distinction).
13. Work systemically with the goal of generalisation
A traditional approach focuses on learnability of the sound. A systemic approach emphasises phonological restructuring of the sound system, and expected changes, due to generalisation, are system-wide. In a systemic approach, clinicians choose non-stimulable, later developing, phonetically more complex, and linguistically marked sounds, supported by least phonological knowledge.
14. Consider applying the Sonority Sequencing Principle
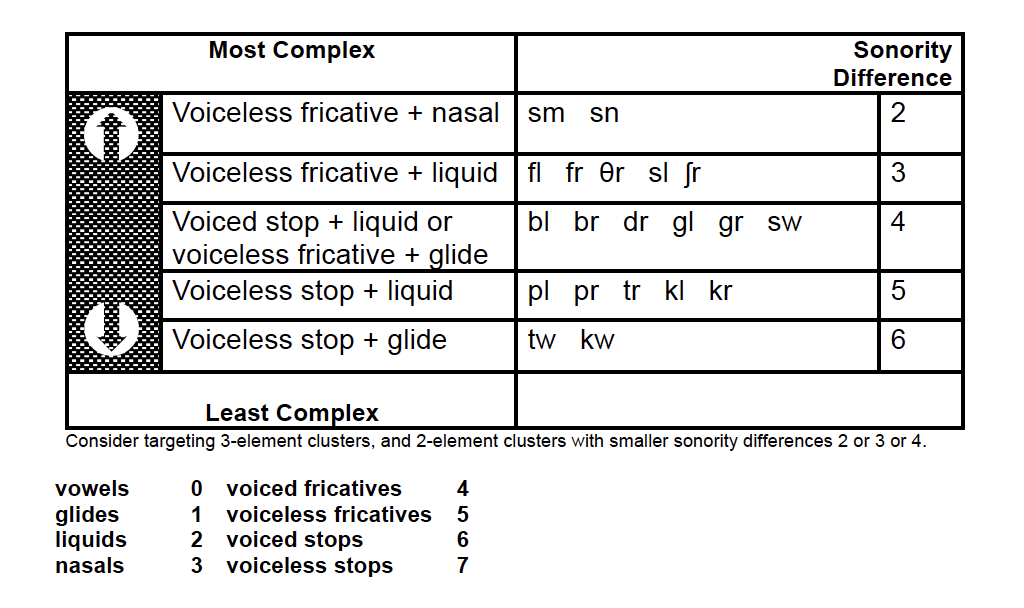
Sonority is the amount of stricture or ‘sound’ in a consonant or vowel (Roca & Johnson, 1999). Steriade (1990) proposed a numerical sonority hierarchy: a list of phones, ordered according to degree of oral stricture and sound. Most sonorous are vowels (= 0), then glides (=1), liquids (= 2), nasals (= 3), voiced fricatives (= 4), voiceless fricatives (=5), voiced stops (=6) and finally the voiceless stops (=7) are least sonorant. We prefer to articulate words with a rise and fall in sonority. For example, in 'tramp'/tɹæmp/ we start with the least sonorous segment (voiceless stop /t/) then liquid /r/ with the vowel /æ/ at the peak, then the less sonorous nasal /m/, finally falling to the least sonorous voiceless stop /p/. This comes more ‘naturally’ to us than [ɹtæpm], even though the segments are the same. This rise-then-fall tendency is called the sonority sequencing principle or SSP.
Consonant clusters are more marked than singletons, but are some clusters more marked than others? One approach to classifying two-element consonant clusters according to markedness is to rank them according to their sonority difference score, using their numerical values from a sonority hierarchy (Ohala, 1999). For example, /kw/ (7 minus 1) has a sonority difference score of 6, whereas /fl/ (5 minus 2) scores 3. Clusters with SMALL sonority differences of 2, 3 or 4 may better promote generalised change to singletons and clusters. Gierut (1999), Gierut & Champion (2001), and Morrisette, Farris & Gierut (2006) provide evidence and target selection guidelines.
15. Consider choosing 'least knowledge' targets
16. Consider Lexical Properties
High frequency words occur often, e.g., come, go, good, look one. They are recognised faster by children than low frequency words.
High neighbourhood density words are phonetically similar to many other words and have 11 or more neighbours.
The words in a neighbourhood are based on one sound substitution (e.g., sat to pat or sat to sit), one sound deletion (e.g., sat to at) or one sound addition (e.g., sat to scat).
‘Bat’ is in a dense neighbourhood of 40 according to the Washington University Speech Lab Neighborhood Database. The 39 neighbours are: back bad badge bag baht bait ban bang bash bass bast batch bath batteau batten batter battle beat bet bight bit boat boot bought bout brat but cat chat fat gnat hat mat pat rat sat tat that vat. ‘Ship’ is in a neighbourhood of 19 so has 18 neighbours: kip sheave shill zip sip nip shin dip gyp rip hip chip lip tip pip sheep shear shop shape.
Children recognise and repeat high-density words slower and less accurately than low-density words which have 10 or fewer neighbours. Also, children name high-density words more accurately than low-density words. This suggests that lexical processing in children entails a high-density disadvantage in recognition and a high-density advantage in production (Storkel, Armbruster & Hogan, 2006).
So, consider using words that are either high frequency or have low neighbourhood density (Storkel & Morrissette, 2002).